

@bic_lib — Библиотека-информационный центр (г. Электросталь)
Библиотека-информационный центр на своей странице в Instagram публикует познавательный и вовлекающий контент, оформленный в едином стиле.

Единая стилистика аккаунта – это те детали, которые объединяют всю визуальную составляющую профиля. Ими могут стать схожие по гамме цвета, одинаковые шрифты, определенный концепт или подача, мелкий реквизит или позинг, расположение самих кадров или же рамки. Миллионы вариаций, где каждый найдет своё.
Как сделать профиль Instagram в одном стиле читайте подробнее здесь: https://instaplus.me/blog/one-style/

Примеры вовлекающего контента в @bic_lib — онлайн игры (например, угадать по глазам писателя) и квизы в сторис. Если Вы хотите расширить охват аудитории, то привлекайте партнёров и разыгрывайте призы, как это делают работники @bic_lib.
Библиотечные профили в Instagram в единой стилистике:
— @libraryforblind — хорошее качество фотографий + полоски в цвет логотипа библиотеки — вуаля! — со вкусом оформленный аккаунт готов!— @novaya_smena89 — одинаковый шрифт для постов, использование графических элементов в одной цветовой гамме (бирюзовый, пурпурный, белый, черный) делает профиль Библиотечно-информационного центра «Новая Смена» узнаваемым и гармоничным;— @bib_r.solntseva_6 — узнать профиль в ленте легко благодаря яркому, контрастному фильтру, который используется для фотоотчётов;— @lermontovborodino — качественные фотографии + рамки. А рамки — это замечательный инструмент и важная деталь, которая поможет объединить весь контент воедино. Пространство здесь открыто для экспериментов, фактур, оттенков и особенного настроения, излучаемого от каждой фотографии.
С чего все начиналось
Когда в мексиканском сенате советом по делам культуры и искусства города Монтеррей был поднят вопрос о создании места, где можно было бы в тишине и комфорте почитать художественную книгу или изучить исторические документы, не всеми членами конгресса он был поддержан. Они объясняли свое нежелание тратить государственные деньги впустую – ведь есть более важные вопросы. Но в конечном итоге было решено – публичной библиотеке быть!
По итогам решения был объявлен творческий конкурс на проект современной библиотеки. Дизайнерскими студиями страны было предложено огромное количество вариантов, среди которых встречались довольно оригинальные и креативные разработки. Победителем в объявленном конкурсе стала студия Аnagrama, проект которой получил наибольшее количество голосов. Нестандартные идеи авторов, отражающие устремления современной молодежи, были воплощены в жизнь. В результате в городе Монтеррей появилась публичная библиотека, аналогов которой нет ни в одной другой стране.

Выходим на рабочий режим
В таком режиме решаем несколько соревнований. С каждым разом замечаем, что записей на листках становится все меньше и меньше, а кода в модулях все больше и больше. Постепенно задача анализа сводится к тому, что вы просто читаете описание решения, говорите ага, ого, ах вот оно как! И добавляете в себе в копилку одно-два новых заклинания или подхода.
После этого режим меняется на режим работы над ошибками. База у вас уже готова, теперь ее просто надо правильно применять. После каждого соревнования, читая описание решений, смотрите — что вы не сделали, что можно было сделать лучше, что вы упустили, ну или где вы конкретно лажанулись, как у меня случилось в Toxic. Шел достаточно хорошо, в подбрюшье золота, а на private улетел вниз на 1500 позиций. Обидно до слез… но успокоился, нашел ошибку, написал пост в слаке — и выучил урок.
Признаком окончательного выхода на рабочий режим может служить тот факт, что одно из описаний топового решения будет написано от вашего никнейма.
Что примерно должно быть в пайплайнах к концу данного этапа:
- Всевозможные варианты предобработки и создания числовых фичей — проекции, отношения,
- Различные методы работы с категориями — Mean target encoding в правильном варианте, частоты, label / ohe,
- Различные схемы ембеддингов над текстом (Glove, Word2Vec, Fasttext)
- Различные схемы векторизации текста (Count, TF-IDF, Hash)
- Несколько валидационных схем (N*M для стандартной кросс-валидации, time-based, by group)
- Bayesian optimization / hyperopt / что-то еще для подбора гиперпараметров
- Shuffle / Target permutation / Boruta / RFE — для отбора фич
- Линейные модели — в едином стиле над одним набором данных
- LGB/XGB/Catboost — в едином стиле над одним набором данных
Автор сделал метаклассы отдельно для линейных и tree-based моделей, с единым внешним интерфейсом, чтобы нивелировать различия в API у разных моделей. Зато теперь можно в едином ключе одной строчкой запускать, например, LGB или XGB над одним обработанным набором данных.
- Несколько нейронных сетей на все случаи жизни (не берем пока картинки) — embeddings/CNN/RNN для текста, RNN для последовательностей, Feed-Forward для всего остального. Хорошо еще понимать и уметь автоенкодеры.
- Ансамбль на базе lgb/regression/scipy — для задач регрессии и классификации
- Хорошо еще уже уметь Genetic Algorithms, иногда они хорошо заходят
Основная цель
Ваша задача написать пайплайны (оформленные в виде jupyter notebooks + модули) для следующих задач:
- EDA (exploratory data analysis). Тут надо сделать замечание — на Kaggle есть специально обученные люди :), которые в каждом соревновании пилят сногсшибательные EDA кернелы. Переплюнуть их у вас вряд-ли получится, но понимать, как можно смотреть на данные все-равно придется, т.к. В боевых задачах этим специально обученным человеком будете вы. Поэтому изучаем подходы, расширяем наши библиотеки.
- Data Cleaning — все, что касается очистки данных. Выбросы, пропуски, и т.д.
- Data preparation — все, что касается подготовки данных для модели. Несколько блоков:
- Общий
- Для регрессий/нейронных сетей
- Для деревьев
- Специальный (временные ряды, картинки, FM/FFM)
- Текст (Vectorizers, TF-IDF, Embeddings)
- Models
- Linear models
- Tree models
- Neural Networks
- Exotic (FM/FFM)
- Feature selection
- Hyperparameters search
- Ensemble
В кернелах обычно все эти задачи собраны в единый код, что и понятно, но очень рекомендую для каждой из этих подзадач завести отдельный ноутбук и отдельный модуль (набор модулей). Так вам потом будет проще.
Предупреждая возможный холивар — структура данного фреймворка не истина в последней инстанции, есть много других способов структурировать свои пайплайны- это всего лишь один из них.
Данные передаются между модулями либо в виде CSV, либо feather/pickle/hdf — что вам удобнее и к чему вы привыкли или лежит душа.
На самом деле много еще зависит и от количества данных, в TalkingData, например, пришлось идти через memmap, чтобы обойти нехватку памяти при создании датасета для lgb.
В остальных случаях — основные данные хранятся в hdf/feather, что-то маленькое (типа набора выбранных атрибутов) — в CSV. Повторюсь — шаблонов нет, кто к чему привык, с тем и работайте.










Самовоспроизведение и информация
| Рисующие руки |
В заключение мы рассмотрим аспекты
творчества Эшера, относящиеся к теории
информации и искусственному интеллекту.
Эта область творчества художника широко
освещена во многих статьях и книгах.
Наиболее полное исследование этого вопроса
освещено в книге Дугласа Хофстадтера (Douglas R.
Hofstadter) “Гёдель, Эшер, Бах: Бесконечная
золотая нить” (Godel, Escher, Bach: An Eternal Golden Braid),
выпущенной в 1980 году и награжденной
пулитцеровской премией.
| Рыбы и чешуйки |
Центральная идея самовоспроизведения,
взятая на вооружение Эшером, обращается к
загадке человеческого сознания и
способности человеческого мозга
обрабатывать информацию так, как не сможет
обработать ни один компьютер. Литографии
“Рисующие руки” и “Рыбы и чешуйки”
используют эту идею разными способами.
Самовоспроизведение является направленным
действием. Руки рисуют друг друга, создавая
самих себя. При этом сами руки и процесс их
самовоспроизведения неразделимы. В работе
“Рыбы и чешуйки” концепция
самовоспроизведения представлена более
функционально, и в данном случае она может
быть названа самоподобием. В этом смысле
данная работа описывает не только рыб, а все
живые организмы, в том числе и человека.
Конечно, мы не состоит из уменьшенных копий
самих себя, но каждая клетка нашего тела
несет в себе информацию обо всем теле в виде
ДНК.
| Три сферы II |
Углубляясь в изучение
самовоспроизведения,
можно его обнаружить в отражении и
пересечении отражений реального мира.
Такое пересечение встречается во многих
картинах Эшера. Мы рассмотрим лишь один
пример – литографию “Три сферы”, на
которой присутствуют три шаровидных тела,
сделанных из разных материалов с различной
отражающей способностью. Эти сферы
отражают друг друга и художника, и комнату,
в которой он работает, и лист бумаги, на
котором он рисует сферы. Хофстадтер в своей
книге написал “… каждая частица мира
содержит в себе весь мир и содержится к во
всех других частицах мира…”.
Таким образом, мы заканчиваем тем же, с
чего начали, – автопортретом художника – его
отражением в своей работе.
Заключение
Мы рассмотрели лишь небольшую часть работ
из сотен набросков и литографий и гравюр,
оставшихся после смерти Эшера в 1972 году
Еще
многое будет сказано и уже сказано о
значении и важности его работ. С каждым
годом появляется все больше и больше книг,
где освещается творчество художника,
анализируются различные аспекты его
творчества
Надеемся, что мы заинтересовали
вас творчеством Эшера.
Англоязычный источник статьи
можно найтиhttp://www.mathacademy.com/pr/minitext/escher/
Перевод Влада Алексеева.
Основные библиотеки Python
Вот базовые библиотеки, которые делают из языка программирования Python инструмент для анализа и визуализации данных. Иногда их называют SciPy Stack. На них основываются более специализированные библиотеки.
Jupyter
Интерактивная оболочка для языка Python. В ней есть дополнительный командный синтаксис; она сохраняет историю ввода во всех сеансах, подсвечивает и автоматически дополняет код. Если вы когда-либо пользовались Mathematica или MATLAB, то разберетесь и в Jupyter.
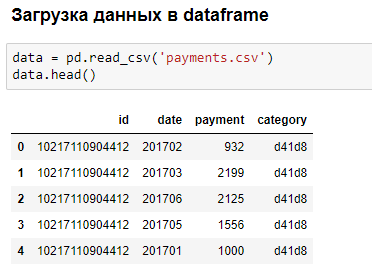
Интерфейс библиотеки подходит для исследования и первичной обработки данных, тестирования первых версий кода и его улучшения. Используя язык разметки Markdown для форматирования текста и библиотеки для визуализации, можно формировать аналитические отчеты в браузере или преобразовать отчет в презентацию. С помощью JupyterHub можно настроить совместную работу команды на сервере.
Пример небольшого анализа данных в браузере:




NumPy
NumPy — основная библиотека Python, которая упрощает работу с векторами и матрицами. Содержит готовые методы для разных математических операций: от создания, изменения формы, умножения и расчета детерминанта матриц до решения линейных уравнений и сингулярного разложения. Например, возьмем такую систему уравнений:
Чтобы ее решить, достаточно воспользоваться методом lialg.solve:
import numpy as npleft = np.array( , ] )right = np.array( )np.linalg.solve(left, right)Ответ: array()
SciPy
Библиотека SciPy основывается на NumPy и расширяет ее возможности. SciPy похожа на Matlab. Включает методы линейной алгебры и методы для работы с вероятностными распределениями, интегральным исчислением и преобразованиями Фурье. расчета определителя двумерной матрицы:
from scipy import linalgimport numpy as np#define square matrixtwo_d_array = np.array(, ])#pass values to det() functionlinalg.det( two_d_array )
Matplotlib
Matplotlib — низкоуровневая библиотека для создания двумерных диаграмм и графиков. С ее помощью можно построить любой график, но для сложной визуализации потребуется больше кода, чем в продвинутых библиотеках.
Пример визуализации:

Используемый код:
import matplotlib.pyplot as pltimport numpy as npt = np.arange(0.0, 2.0, 0.01)s = 1 + np.sin(2*np.pi*t)plt.plot(t, s)plt.xlabel(‘time (s)’)plt.ylabel(‘voltage (mV)’)plt.title(‘About as simple as it gets, folks’)plt.grid(True)plt.savefig(«test.png»)plt.show()










LibGen в IPFS
И хотя социальная значимость LibGen очевидна, столь же очевидны причины, из-за которых библиотека постоянно находится под угрозой закрытия. Именно это сподвигает мейнтейнеров зеркал искать новые пути обеспечения устойчивости. Одним из таких путей стала публикация коллекции в IPFS.
IPFS появился относительно давно. На технологию при её появлении возлагались большие надежды и не все из них оправдались. Тем не менее, развитие сети продолжается, а появление в ней LibGen может усилить приток свежих сил и сыграть на руку самой сети.
Упрощая до предела, IPFS можно назвать файловой системой, натянутой на неопределенное количество узлов сети. Участники одноранговой сети могут кешировать файлы у себя и раздавать их окружающим. Адресация файлов происходит не по путям, а по хешу от содержания файла.
Некоторое время назад участники LibGen анонсировали IPFS-хеши и встали на раздачу файлов. На этой неделе ссылки на файлы в IPFS стали появляться в результатах поиска некоторых зеркал LibGen. Кроме того, благодаря действиям активистов команды Internet Archive и освещению происходящего на reddit, сейчас идет наплыв дополнительных сидеров как в IPFS, так и на раздачу оригинальных торрентов.
Пока неизвестно, появятся ли сами хеши IPFS в дампах базы LibGen, но кажется, что этого стоит ожидать. Возможность скачать метаданные коллекции вместе с IPFS-хешами снизит порог входа для создания собственного зеркала, увеличит стабильность всей библиотеки и приблизит исполнение мечты создателей библиотеки.
P.S. Для желающих помочь проекту создан ресурс freeread.org, на нем живут инструкции как настроить IPFS.
Как правильно использовать библиотеки
Когда библиотека опубликована для команды, её компоненты появляются на вкладке Assets в левой панели. После этого участники могут их использовать.
Поместить экземпляр компонента в дизайн можно тремя способами:
- Скопировать. Копия основного компонента или его копии автоматически становится экземпляром.
- Перетащить. Из меню Assets в рабочую область.
- Изменить. На правой панели у экземпляров есть параметр Instance. Здесь нужный основной компонент можно выбрать из списка.
Бывает, что изменённый экземпляр уже сильно отличается от «родителя». Если он ещё понадобится в таком виде, можно сделать две вещи:
Библиотеки для работы с данными
Библиотеки Python для анализа данных, Machine Learning и обучения сложных нейронных сетей.
Scikit-learn
Scikit-learn основана на NumPy и SciPy. В ней есть алгоритмы для машинного обучения и интеллектуального анализа данных: кластеризации, регрессии и классификации. Это одна из самых лучших библиотек для компаний, работающих с огромным объемом данных — ее используют Evernote, OKCupid, Spotify и Birchbox.
визуализации частичной зависимости стоимости домов в Калифорнии в зависимости от особенностей местности:
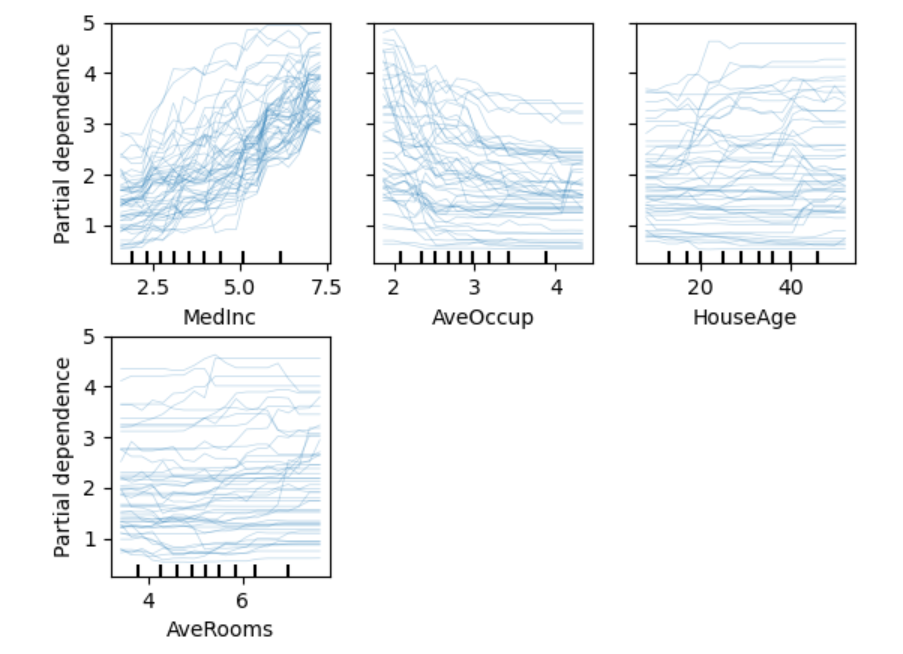
Используемый код:
from sklearn.ensemble import RandomForestRegressorfrom sklearn.datasets import fetch_california_housingfrom sklearn.inspection import plot_partial_dependenceX, y = fetch_california_housing(return_X_y=True, as_frame=True)features = est = RandomForestRegressor(n_estimators=10)est.fit(X, y)display = plot_partial_dependence(est, X, features, kind=»individual», subsample=50,n_jobs=3, grid_resolution=20, random_state=0)display.figure_.suptitle(‘Partial dependence of house value on non-location features\n’‘for the California housing dataset, with BayesianRidge’)display.figure_.subplots_adjust(hspace=0.3)
TensorFlow
Библиотеку создали в Google, чтобы заменить DistBelief — фреймворк для обучения, настройки и тренировки нейронных сетей. Благодаря этой библиотеке Google может определять объекты на фотографиях, а приложение для распознавания голоса — понимать речь.
Пример архитектуры сверточной нейронной сети:
Model: «sequential»_________________________________________________________________Layer (type) Output Shape Param #=================================================================conv2d (Conv2D) (None, 30, 30, 32) 896_________________________________________________________________max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0_________________________________________________________________conv2d_1 (Conv2D) (None, 13, 13, 64) 18496_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0_________________________________________________________________conv2d_2 (Conv2D) (None, 4, 4, 64) 36928_________________________________________________________________flatten (Flatten) (None, 1024) 0_________________________________________________________________dense (Dense) (None, 64) 65600_________________________________________________________________dense_1 (Dense) (None, 10) 650=================================================================Total params: 122,570Trainable params: 122,570Non-trainable params: 0_________________________________________________________________
Keras
Библиотека глубокого обучения. Благодаря модульности и масштабированию она позволяет легко и быстро создавать прототипы. Keras поддерживает как сверточные и рекуррентные сети, так и их комбинации.
Пример кода обучения модели по классификации изображений:
epochs = 50callbacks = model.compile(optimizer=keras.optimizers.Adam(1e-3),loss=»binary_crossentropy»,metrics=,)model.fit(train_ds, epochs=epochs, callbacks=callbacks, validation_data=val_ds,)










Бэкенды
Бэкенды — это то, из-за чего Keras стал известен и популярен (помимо прочих достоинств, которые мы разберем ниже). Keras позволяет использовать в качестве бэкенда разные другие фреймворки. При этом написанный вами код будет исполняться независимо от используемого бэкенда. Начиналась разработка, как мы уже говорили, с Theano, но со временем добавился Tensorflow. Сейчас Keras по умолчанию работает именно с ним, но если вы хотите использовать Theano, то есть два варианта, как это сделать:
- Отредактировать файл конфигурации keras.json, который лежит по пути (или в случае операционных систем семейства Windows). Нам нужно поле :
- Второй путь — это задать переменную окружения , например, так:
Стоит отметить, что сейчас ведется работа по написанию биндингов для CNTK от Microsoft, так что через некоторое время появится еще один доступный бэкенд. Следить за этим можно здесь.
Также существует MXNet Keras backend, который пока не обладает всей функциональностью, но если вы используете MXNet, вы можете обратить внимание на такую возможность. Еще существует интересный проект Keras.js, дающий возможность запускать натренированные модели Keras из браузера на машинах, где есть GPU
Еще существует интересный проект Keras.js, дающий возможность запускать натренированные модели Keras из браузера на машинах, где есть GPU.
Так что бэкенды Keras ширятся и со временем захватят мир! (Но это неточно.)
Библиотеки Python для визуализации
Библиотеки, которые пригодятся в визуализации данных и построении графиков.
Seaborn
Библиотека более высокого уровня, чем matplotlib. С ее помощью проще создавать специфическую визуализацию: тепловые карты, временные ряды и скрипичные диаграммы. Пример визуализации:

Используемый код:
import seaborn as snssns.set(style=»whitegrid», palette=»pastel», color_codes=True)# Load the example tips datasettips = sns.load_dataset(«tips»)# Draw a nested violinplot and split the violins for easier comparisonsns.violinplot(x=»day», y=»total_bill», hue=»sex», data=tips, split=True,inner=»quart», palette={«Male»: «b», «Female»: «y»})sns.despine(left=True)
Bokeh
Создает интерактивные и масштабируемые графики в браузерах, используя виджеты JavaScript. Сложность графиков может быть разная: от стандартных диаграмм до сложных кастомизированных схем. Примеры визуализации:

Используемый код:
import numpy as npfrom bokeh.layouts import gridplotfrom bokeh.plotting import figure, show, output_filex = np.linspace(0, 4*np.pi, 100)y = np.sin(x)TOOLS = «pan,wheel_zoom,box_zoom,reset,save,box_select»p1 = figure(title=»Legend Example», tools=TOOLS)p1.circle(x, y, legend=»sin(x)»)p1.circle(x, 2*y, legend=»2*sin(x)», color=»orange»)p1.circle(x, 3*y, legend=»3*sin(x)», color=»green»)p2 = figure(title=»Another Legend Example», tools=TOOLS)p2.circle(x, y, legend=»sin(x)»)p2.line(x, y, legend=»sin(x)»)p2.line(x, 2*y, legend=»2*sin(x)», line_dash=(4, 4), line_color=»orange», line_width=2)p2.square(x, 3*y, legend=»3*sin(x)», fill_color=None, line_color=»green»)p2.line(x, 3*y, legend=»3*sin(x)», line_color=»green»)output_file(«legend.html», title=»legend.py example»)show(gridplot(p1, p2, ncols=2, plot_width=400, plot_height=400)) # open a browser
Basemap
Basemap используется для создания карт. На ее основе сделана библиотека Folium, с помощью которой создают интерактивные карты в интернете. Пример карты:

Код:
import numpy as npfrom mpl_toolkits.basemap import Basemapimport matplotlib.pyplot as pltfrom datetime import datetime# miller projectionmap = Basemap(projection=’mill’,lon_0=180)# plot coastlines, draw label meridians and parallels.map.drawcoastlines()map.drawparallels(np.arange(-90,90,30),labels=)map.drawmeridians(np.arange(map.lonmin,map.lonmax+30,60),labels=)# fill continents ‘coral’ (with zorder=0), color wet areas ‘aqua’map.drawmapboundary(fill_color=’aqua’)map.fillcontinents(color=’coral’,lake_color=’aqua’)# map shows through. Use current time in UTC.date = datetime.utcnow()CS=map.nightshade(date)plt.title(‘Day/Night Map for %s (UTC)’ % date.strftime(«%d %b %Y %H:%M:%S»))plt.show()
NetworkX
Используется для создания и анализа графов и сетевых структур. Предназначена для работы со стандартными и нестандартными форматами данных. Примеры визуализации:











Используемый код:
# Author: Aric Hagberg (hagberg@lanl.gov)# Copyright (C) 2004-2018 by# Aric Hagberg
Это малая часть библиотек Python, но и их достаточно, чтобы на серьезном уровне анализировать данные, создавать и обучать нейронные сети и визуализировать результаты.
Библиотеки Python — это файлы с шаблонами кода. Их придумали для того, чтобы людям не приходилось каждый раз заново набирать один и тот же код: они просто открывают файл, вставляют свои данные и получают нужный результат. В этом материале даем описание библиотек, которые используются чаще всего для анализа данных на Python.
О LibGen
В начале нулевых в пока ещё свободном от регулирования интернете лежали дюжины сборников научных книг. Крупнейшие коллекции из тех, что я могу вспомнить – KoLXo3, mehmat и mirknig – содержали к 2007 году десятки тысяч учебников, публикаций и других важных djvuшек и pdfок для студентов.
Как и любые другие свалки файлов, эти коллекции страдали от общих проблем с навигацией. Библиотека Колхоз, например, жила на 20+ DVD-дисках. Наиболее востребованная часть библиотеки руками старшаков переселялась в файловую шару общежития, а если нужно было что-то редкое, то горе тебе! Как минимум ты попадал на пиво для хозяина дисков.
Тем не менее, коллекции были все ещё осязаемых размеров. И хотя поиск по названиям самих файлов зачастую разбивался о креативность создателя файла, ручным full-scanом можно было вытащить нужную книгу после упорного проматывания десятка страниц.
В 2008 году на rutracker.ru (тогда torrents.ru) энтузиастом были опубликованы торренты, скомпоновавшие существовавшие сборники книг в одну большую кучу. В этом же треде нашелся человек, начавший кропотливую работу по систематизации выложенных файлов и созданию веб-интерфейса. Так появился Library Genesis.
Все это время с 2008 года и до текущего момента LibGen развивался и пополнял собственные книжные полки силами соообщества. Метаданные книг редактировались, а затем сохранялись и распространялись в виде дампов MySQL для всех желающих. Альтруистическое отношение к метаданным привело к появлению большого количества зеркал и повышению выживаемости всего проекта, несмотря на возросшую фрагментацию.
Важной вехой в жизни библиотеки стало зеркалирование базы данных Sci-Hub, стартовавшее в 2013 году. Благодаря коллаборации двух систем в одном месте оказался сконцентрирован небывалый по качеству набор данных – научные и художественные книги вместе с научными публикациями
У меня есть предположение, что одного дампа совместной базы LibGen и Sci-Hub будет достаточно для восстановления научно-технического прогресса цивилизации в случае его утраты в ходе катастрофы.
Сегодня библиотека довольно устойчиво держится на плаву, имеет веб-интерфейс, позволяющий искать по коллекции и скачивать найденные файлы.
Спирали
| Спирали |
| Водовороты |
Странно, но в оригинальной работе обошли
вниманием целый класс фигур, которые
достаточно часто встречаются в работах
Эшера. Это закрученные в спирали фигуры
В
работе “Спирали” мы видим четыре
закручивающиеся в спираль полоски, которые
постоянно сближаются и постепенно закручиваются
сами в себя, образуя своеобразный тор. Пройдя целый
круг, спираль заходит внутрь самой себя,
образуя тем самым, как бы, спираль второго
порядка – спираль в спирали.
В работе “Водовороты” Эшер объединил
спиралевидную форму и свой излюбленный
художественный прием – регулярное разбиение плоскости
(или мозаику). Здесь рыбы,выплыв из одного
водоворота, попадают во второй и, погружась
в него, постепенно уменьшаются в размерах и
наконец совсем исчезают
Обратите внимание
на постепенно уменьшающуюся в размерах
мозаику. Если мысленно развернуть спираль,
то мы увидим лишь два ряда рыб, плывущих
навстречу друг другу
Но скрученные в
спираль и соответствующим образом
деформированные образы рыб полностью
покрывают некоторую область бесконечной
плоскости.
| Сферические спирали |
Иной способ представления спирали
использован в работе “Сферические
спирали”, где четыре полосы расположены
на поверхности шара, проходя от одного
полюса шара к другому. Похожий путь может
пройти самолет, летящий с северного полюса
земного шара на южный.






Здесь мы привели основные виды спиралей,
использованных Эшером в своих работах.
Различные их модификации можно обнаружить
и на многих других литографиях художника.
Что такое библиотека компонентов
Библиотека — это файл, где хранятся основные компоненты для проекта. Он точно такой же, как файл с готовым дизайном, — отличается только назначением. Если нужно добавить в проект один из стандартных элементов, дизайнер не рисует его заново, а берёт из библиотеки.
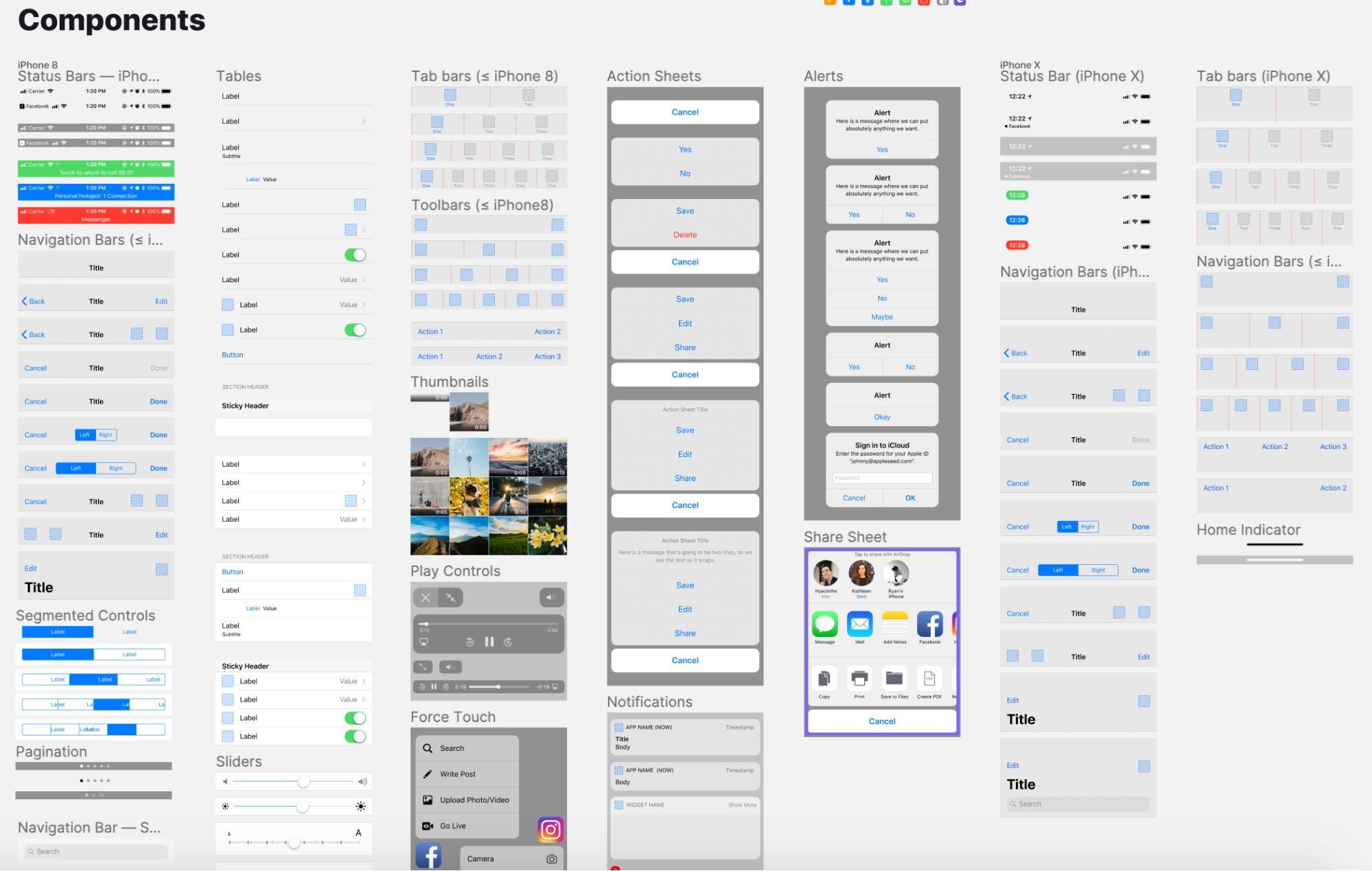
Фрагмент библиотеки компонентов Facebook iOS 11 UI Kit, содержащей все визуальные элементы приложения Facebook.
Для библиотек нет строгих стандартов оформления. Обычно компоненты структурируют и снабжают заголовками. Их удобно группировать по фреймам — например, в зависимости от интерфейса (мобильный или десктопный) и типа (уведомления, контекстные меню и тому подобное).
Заключение
Вот и все, мы сделали первые модели на Keras! Надеемся, что предоставляемые им возможности заинтересовали вас, так что вы будете его использовать в своей работе.
Пришло время обсудить плюсы и минусы Keras. К очевидным плюсам можно отнести простоту создания моделей, которая выливается в высокую скорость прототипирования. Например, авторы недавней статьи про спутники использовали именно Keras. В целом этот фреймворк становится все более и более популярным:
Keras за год догнал Torch, который разрабатывается уже 5 лет, судя по упоминаниям в научных статьях. Кажется, своей цели — простоты использования — Франсуа Шолле (François Chollet, автор Keras) добился. Более того, его инициатива не осталась незамеченной: буквально через несколько месяцев разработки компания Google пригласила его заниматься этим в команде, разрабатывающей Tensorflow. А также с версии Tensorflow 1.2 Keras будет включен в состав TF (tf.keras).
Также надо сказать пару слов о недостатках. К сожалению, идея Keras о универсальности кода выполняется не всегда: Keras 2.0 поломал совместимость с первой версией, некоторые функции стали называться по-другому, некоторые переехали, в общем, история похожа на второй и третий python. Отличием является то, что в случае Keras была выбрана только вторая версия для развития. Также код Keras работает на Tensorflow пока медленнее, чем на Theano (хотя для нативного кода фреймворки, как минимум, сравнимы).
В целом, можно порекомендовать Keras к использованию, когда вам нужно быстро составить и протестировать сеть для решения конкретной задачи. Но если вам нужны какие-то сложные вещи, вроде нестандартного слоя или распараллеливания кода на несколько GPU, то лучше (а подчас просто неизбежно) использовать нижележащий фреймворк.
Практически весь код из статьи есть в виде одного ноутбука здесь. Также очень рекомендуем вам документацию по Keras: keras.io, а так же официальные примеры, на которых эта статья во многом основана.
Пост написан в сотрудничестве с Wordbearer.





